Attention conservaton notice: this post is just data munging to get a csv with HSPA metadata shipshape. Tried to set it to status: hidden so it wouldn't show on the front page of the blog, but had some trouble with Pelican. That said, work has to get done, so better to do it in an .Rmd and write down what I was thinking - I've learned that lesson like a thousand times. If you are in the small group of people who care about this sort of thing, get in touch.
First, read in the csv. This proved to be kind of a headache:
the format of the HSPA file layout is totally different from the NJASK file (sigh). The key difference is that the spanning headers that indicate the subgroup (gen ed, special ed, etc) are indicated as have start/end position across the whole relevant range in the NJASK file, but on the HSPA file they only show up as 6 character fields before the relevant range. I hand-edited the HSPA file so it would be consistent with the NJASK file.
NJASK:
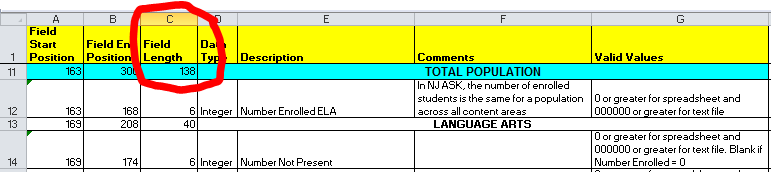
HSPA:
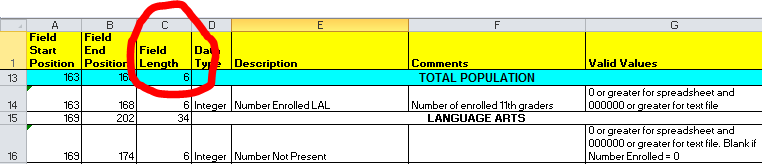
This.... I can't say anything nice about the decision to do this (why?!?) so I'm just going to move on.
hspa <- readr::read_csv(paste0(final_path, "datasets/hspa_layout.csv"))
## Error: 'datasets/hspa_layout.csv' does not exist in current working directory ('/Users/almartin/Google Drive/repositories/almart.in-source/content/pages').
names(hspa) <- tolower(gsub(' ', '_', names(hspa)))
## Error in gsub(" ", "_", names(hspa)): object 'hspa' not found
head(hspa)
## Error in head(hspa): object 'hspa' not found
Let's rework the code from the first post into a proper function.
library(sqldf)
library(magrittr)
library(dplyr)
library(reshape2)
process_layout <- function(df) {
require(sqldf)
require(magrittr)
require(dplyr)
require(reshape2)
#split spanners from keepers
spanners <- dplyr::filter(df, structural==TRUE)
keepers <- dplyr::filter(df, structural==FALSE)
#join spanners to keepers
with_spanners <- sqldf('
SELECT keepers.*
,spanners.data_type AS spanner
,spanners.field_length AS spanner_length
FROM keepers
LEFT OUTER JOIN spanners
ON keepers.field_start_position >= spanners.field_start_position
AND keepers.field_end_position <= spanners.field_end_position
')
#tag the joined data frame with a row number to facilitate long -> wide
with_rn <- with_spanners %>%
dplyr::group_by(
field_start_position, field_end_position, field_length,
data_type, description, comments, valid_values
) %>%
mutate(
rn = order(desc(spanner_length))
) %>%
select(
field_start_position, field_end_position, field_length,
data_type, description, comments, valid_values, spanner, rn
) %>%
as.data.frame()
#text processing and mask NAs
with_rn$rn <- paste0('spanner', with_rn$rn)
with_rn$spanner <- ifelse(is.na(with_rn$spanner),'', with_rn$spanner)
layout_wide <- dcast(
data = with_rn,
formula = field_start_position + field_end_position + field_length +
data_type + description + comments + valid_values ~ rn,
value.var = "spanner"
)
#this appears to be a bug in dcast? should not be needed.
layout_wide$spanner2 <- ifelse(is.na(layout_wide$spanner2),'', layout_wide$spanner2)
reserved_chars <- list('+' = 'and', '(' = '', ')' = '')
for (i in 1:length(reserved_chars)) {
layout_wide$spanner1 <- gsub(
names(reserved_chars)[i],
reserved_chars[i],
layout_wide$spanner1,
fixed = TRUE
)
}
#make final name
layout_wide$final_name <- layout_wide %$% paste(spanner1, spanner2, description, sep='_')
#kill double underscores
layout_wide$final_name <- gsub('__', '_', layout_wide$final_name)
#kill leading or trailer underscores
layout_wide$final_name <- gsub("(^_+|_+$)", "", layout_wide$final_name)
#trim any remaining whitespace
layout_wide$final_name <- gsub("^\\s+|\\s+$", "", layout_wide$final_name)
#all whitespace becomes underscore
layout_wide$final_name <- gsub(' ', '_', layout_wide$final_name)
#more whitespace cleanup
layout_wide$comments <- gsub("^\\s+|\\s+$", "", layout_wide$comments)
layout_wide$description <- gsub("^\\s+|\\s+$", "", layout_wide$description)
layout_wide$valid_values <- gsub("^\\s+|\\s+$", "", layout_wide$valid_values)
return(layout_wide)
}
layout_hspa <- process_layout(hspa)
## Error in filter_(.data, .dots = lazyeval::lazy_dots(...)): object 'hspa' not found
layout_hspa %>% head()
## field_start_position field_end_position field_length data_type
## 1 1 9 9 Text
## 2 1 9 9 Text
## 3 1 2 2 Text
## 4 3 6 4 Text
## 5 7 9 3 Text
## 6 10 59 50 Text
## description comments
## 1 RECORD KEY
## 2 CDS Code
## 3 County Code
## 4 District Code Applicable only for district and school aggregations.
## 5 School Code Applicable only for school aggregations.
## 6 County Name
## valid_values
## 1
## 2 CDS codes for schools and districts\nTHE FIRST TWO POSITIONS WILL INCLUDE THE FOLLOWING AGGREGATION CODES: NS = Non-Special Needs; SN = Special Needs; ST = State; A = DFG A; B = DFG B; CD= DFG CD\x85.
## 3 01, 03, 05, 07, 09, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 80
## 4 0100 to 9999, blank
## 5 001 to 999, blank
## 6 A to Z, blank; Applicable only for district and school aggregations
## spanner1 spanner2 final_name
## 1 RECORD_KEY
## 2 CDS_Code
## 3 County_Code
## 4 District_Code
## 5 School_Code
## 6 County_Name
Finally, save the hspa layout as an .rda file.
save(layout_hspa, file = paste0(final_path,'datasets/hspa_layout.rda'))
## Warning in gzfile(file, "wb"): cannot open compressed file 'datasets/
## hspa_layout.rda', probable reason 'No such file or directory'
## Error in gzfile(file, "wb"): cannot open the connection
old HSPA
Before 2010 the HSPA used a different layout. Prep that layout file:
Read:
hspa2010 <- readr::read_csv(paste0(final_path, "datasets/hspa2010_layout.csv"))
## Error: 'datasets/hspa2010_layout.csv' does not exist in current working directory ('/Users/almartin/Google Drive/repositories/almart.in-source/content/pages').
names(hspa2010) <- tolower(gsub(' ', '_', names(hspa2010)))
## Error in gsub(" ", "_", names(hspa2010)): object 'hspa2010' not found
head(hspa2010)
## Error in head(hspa2010): object 'hspa2010' not found
One note here: the layout at flat file has headers for science, even though it isn't on the HSPA. I'm omitting the last set of science headers in my layout file, because the raw files on the state website don't appear to be padded with enough blanks for the last NA slots.
Process:
layout_hspa2010 <- process_layout(hspa2010)
## Error in filter_(.data, .dots = lazyeval::lazy_dots(...)): object 'hspa2010' not found
layout_hspa2010 %>% head()
## field_start_position field_end_position field_length data_type
## 1 1 9 9 Text
## 2 1 9 9 Text
## 3 1 2 2 Text
## 4 3 6 4 Text
## 5 7 9 3 Text
## 6 10 59 50 Text
## description comments
## 1 RECORD KEY
## 2 CDS Code
## 3 County Code
## 4 District Code Applicable only for district and school aggregations.
## 5 School Code Applicable only for school aggregations.
## 6 County Name
## valid_values
## 1
## 2 CDS codes for schools and districts\nTHE FIRST TWO POSITIONS WILL INCLUDE THE FOLLOWING AGGREGATION CODES: NS = Non-Special Needs; SN = Special Needs; ST = State; A = DFG A; B = DFG B; CD= DFG CD\x85.
## 3 01, 03, 05, 07, 09, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 80
## 4 0100 to 9999, blank
## 5 001 to 999, blank
## 6 A to Z, blank; Applicable only for district and school aggregations
## spanner1 spanner2 final_name
## 1 RECORD_KEY
## 2 CDS_Code
## 3 County_Code
## 4 District_Code
## 5 School_Code
## 6 County_Name
Save:
save(layout_hspa2010, file = paste0(final_path, 'datasets/hspa2010_layout.rda'))
## Warning in gzfile(file, "wb"): cannot open compressed file 'datasets/
## hspa2010_layout.rda', probable reason 'No such file or directory'
## Error in gzfile(file, "wb"): cannot open the connection
GEPA
Now do the same for the GEPA layout, using the functions developed above:
Read:
gepa <- readr::read_csv(paste0(final_path, 'datasets/gepa_layout.csv'))
## Error: 'datasets/gepa_layout.csv' does not exist in current working directory ('/Users/almartin/Google Drive/repositories/almart.in-source/content/pages').
names(gepa) <- tolower(gsub(' ', '_', names(gepa)))
## Error in gsub(" ", "_", names(gepa)): object 'gepa' not found
head(gepa)
## Error in head(gepa): object 'gepa' not found
Process:
layout_gepa <- process_layout(gepa)
## Error in filter_(.data, .dots = lazyeval::lazy_dots(...)): object 'gepa' not found
layout_gepa %>% head()
## field_start_position field_end_position field_length data_type
## 1 1 9 9 Text
## 2 1 2 2 Text
## 3 3 6 4 Text
## 4 7 9 3 Text
## 5 10 59 50 Text
## 6 60 109 50 Text
## description comments
## 1 CDS Code
## 2 County Code
## 3 District Code
## 4 School Code
## 5 County Name
## 6 District Name
## valid_values
## 1 CDS codes for schools and districts\nTHE FIRST TWO POSITIONS WILL INCLUDE THE FOLLOWING AGGREGATION CODES: NS = Non-Special Needs; SN = Special Needs; ST = State; A = DFG A; B = DFG B; CD= DFG CD\x85.
## 2 01, 03, 05, 07, 09, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 80, ST, A, B, CD, DE, FG, GH, I, J, R, NS, SN
## 3 0100 to 9999; Applicable only for district and school aggregations
## 4 001 to 999; Applicable only for school aggregations
## 5 A to Z, blank; Applicable only for district and school aggregations
## 6 A to Z, blank; Applicable only for district and school aggregations
## spanner1 spanner2 final_name
## 1 CDS_Code
## 2 County_Code
## 3 District_Code
## 4 School_Code
## 5 County_Name
## 6 District_Name
Save:
save(layout_gepa, file = paste0(final_path, 'datasets/gepa_layout.rda'))
## Warning in gzfile(file, "wb"): cannot open compressed file 'datasets/
## gepa_layout.rda', probable reason 'No such file or directory'
## Error in gzfile(file, "wb"): cannot open the connection
old NJASK
repeat for old NJASK
Read:
njask05 <- readr::read_csv(paste0(final_path, 'datasets/njask2005_layout.csv'))
## Error: 'datasets/njask2005_layout.csv' does not exist in current working directory ('/Users/almartin/Google Drive/repositories/almart.in-source/content/pages').
names(njask05) <- tolower(gsub(' ', '_', names(njask05)))
## Error in gsub(" ", "_", names(njask05)): object 'njask05' not found
head(njask05)
## Error in head(njask05): object 'njask05' not found
Process:
layout_njask05 <- process_layout(njask05)
## Error in filter_(.data, .dots = lazyeval::lazy_dots(...)): object 'njask05' not found
layout_njask05 %>% head()
## field_start_position field_end_position field_length data_type
## 1 1 9 9 Text
## 2 1 2 2 Text
## 3 3 6 4 Text
## 4 7 9 3 Text
## 5 10 59 50 Text
## 6 60 109 50 Text
## description comments
## 1 CDS Code
## 2 County Code
## 3 District Code
## 4 School Code
## 5 County Name
## 6 District Name
## valid_values
## 1 CDS codes for schools and districts\nTHE FIRST TWO POSITIONS WILL INCLUDE THE FOLLOWING AGGREGATION CODES: NS = Non-Special Needs; SN = Special Needs; ST = State; A = DFG A; B = DFG B; CD= DFG CD\x85.
## 2 01, 03, 05, 07, 09, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 80, 90
## 3 0100 to 9999
## 4 001 to 999
## 5 A to Z, blank; Applicable only for district and school aggregations
## 6 A to Z, blank; Applicable only for district and school aggregations
## spanner1 spanner2 final_name
## 1 CDS_Code
## 2 County_Code
## 3 District_Code
## 4 School_Code
## 5 County_Name
## 6 District_Name
layout_njask05 %>% tail()
## field_start_position field_end_position field_length data_type
## 430 2283 2288 6 Integer
## 431 2289 2292 4 Decimal
## 432 2293 2296 4 Decimal
## 433 2297 2300 4 Decimal
## 434 2301 2304 4 Decimal
## 435 2305 2306 2 Integer
## description comments
## 430 Number of Valid Scale Scores
## 431 Partially Proficient Percentage One implied decimal
## 432 Proficient Percentage One implied decimal
## 433 Advanced Proficient Percentage One implied decimal
## 434 Scale Score Mean One implied decimal
## 435 Grade Located in text file only
## valid_values spanner1 spanner2
## 430 0 or greater SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 431 0.0 to 100.0 SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 432 0.0 to 100.0 SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 433 0.0 to 100.0 SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 434 100.0 to 300.0 SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 435 03, 04
## final_name
## 430 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Number_of_Valid_Scale_Scores
## 431 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Partially_Proficient_Percentage
## 432 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Proficient_Percentage
## 433 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Advanced_Proficient_Percentage
## 434 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Scale_Score_Mean
## 435 Grade
Save:
save(layout_njask05, file = paste0(final_path, 'datasets/njask05_layout.rda'))
## Warning in gzfile(file, "wb"): cannot open compressed file 'datasets/
## njask05_layout.rda', probable reason 'No such file or directory'
## Error in gzfile(file, "wb"): cannot open the connection
(2004) old NJASK
once more for 2004 NJASK
Read:
njask04 <- readr::read_csv(paste0(final_path, 'datasets/njask2004_layout.csv'))
## Error: 'datasets/njask2004_layout.csv' does not exist in current working directory ('/Users/almartin/Google Drive/repositories/almart.in-source/content/pages').
names(njask04) <- tolower(gsub(' ', '_', names(njask04)))
## Error in gsub(" ", "_", names(njask04)): object 'njask04' not found
head(njask04)
## Error in head(njask04): object 'njask04' not found
Process:
layout_njask04 <- process_layout(njask04)
## Error in filter_(.data, .dots = lazyeval::lazy_dots(...)): object 'njask04' not found
layout_njask04 %>% head()
## field_start_position field_end_position field_length data_type
## 1 1 9 9 Text
## 2 1 2 2 Text
## 3 3 6 4 Text
## 4 7 9 3 Text
## 5 10 59 50 Text
## 6 60 109 50 Text
## description comments
## 1 CDS Code
## 2 County Code
## 3 District Code
## 4 School Code
## 5 County Name
## 6 District Name
## valid_values
## 1 CDS codes for schools and districts\nTHE FIRST TWO POSITIONS WILL INCLUDE THE FOLLOWING AGGREGATION CODES: NS = Non-Special Needs; SN = Special Needs; ST = State; A = DFG A; B = DFG B; CD= DFG CD\x85.
## 2 01, 03, 05, 07, 09, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 80, 90
## 3 0100 to 9999
## 4 001 to 999
## 5 A to Z, blank; Applicable only for district and school aggregations
## 6 A to Z, blank; Applicable only for district and school aggregations
## spanner1 spanner2 final_name
## 1 CDS_Code
## 2 County_Code
## 3 District_Code
## 4 School_Code
## 5 County_Name
## 6 District_Name
layout_njask04 %>% tail()
## field_start_position field_end_position field_length data_type
## 357 1869 1874 6 Integer
## 358 1875 1878 4 Decimal
## 359 1879 1882 4 Decimal
## 360 1883 1886 4 Decimal
## 361 1887 1890 4 Decimal
## 362 1891 1892 2 Integer
## description comments
## 357 Number of Valid Scale Scores
## 358 Partially Proficient Percentage One implied decimal
## 359 Proficient Percentage One implied decimal
## 360 Advanced Proficient Percentage One implied decimal
## 361 Scale Score Mean One implied decimal
## 362 Grade Located in text file only
## valid_values spanner1 spanner2
## 357 0 or greater SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 358 0.0 to 100.0 SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 359 0.0 to 100.0 SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 360 0.0 to 100.0 SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 361 100.0 to 300.0 SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 362 03, 04
## final_name
## 357 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Number_of_Valid_Scale_Scores
## 358 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Partially_Proficient_Percentage
## 359 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Proficient_Percentage
## 360 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Advanced_Proficient_Percentage
## 361 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Scale_Score_Mean
## 362 Grade
Save:
save(layout_njask04, file = paste0(final_path, 'datasets/njask04_layout.rda'))
## Warning in gzfile(file, "wb"): cannot open compressed file 'datasets/
## njask04_layout.rda', probable reason 'No such file or directory'
## Error in gzfile(file, "wb"): cannot open the connection
2007 gr 3 NJASK
this one used a slightly different layout.
Read:
njask07gr3 <- readr::read_csv(paste0(final_path, 'datasets/njask2007gr3_layout.csv'))
## Error: 'datasets/njask2007gr3_layout.csv' does not exist in current working directory ('/Users/almartin/Google Drive/repositories/almart.in-source/content/pages').
names(njask07gr3) <- tolower(gsub(' ', '_', names(njask07gr3)))
## Error in gsub(" ", "_", names(njask07gr3)): object 'njask07gr3' not found
head(njask07gr3)
## Error in head(njask07gr3): object 'njask07gr3' not found
Process:
layout_njask07gr3 <- process_layout(njask07gr3)
## Error in filter_(.data, .dots = lazyeval::lazy_dots(...)): object 'njask07gr3' not found
layout_njask07gr3 %>% head()
## field_start_position field_end_position field_length data_type
## 1 1 9 9 Text
## 2 1 2 2 Text
## 3 3 6 4 Text
## 4 7 9 3 Text
## 5 10 59 50 Text
## 6 60 109 50 Text
## description comments
## 1 CDS Code
## 2 County Code
## 3 District Code
## 4 School Code
## 5 County Name
## 6 District Name
## valid_values
## 1 CDS codes for schools and districts\nTHE FIRST TWO POSITIONS WILL INCLUDE THE FOLLOWING AGGREGATION CODES: NS = Non-Special Needs; SN = Special Needs; ST = State; A = DFG A; B = DFG B; CD= DFG CD\x85.
## 2 01, 03, 05, 07, 09, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 80, 90
## 3 0100 to 9999; Applicable only for district and school aggregations
## 4 001 to 999; Applicable only for school aggregations
## 5 A to Z, blank; Applicable only for district and school aggregations
## 6 A to Z, blank; Applicable only for district and school aggregations
## spanner1 spanner2 final_name
## 1 CDS_Code
## 2 County_Code
## 3 District_Code
## 4 School_Code
## 5 County_Name
## 6 District_Name
layout_njask07gr3 %>% tail()
## field_start_position field_end_position field_length data_type
## 481 2541 2544 4 Decimal
## 482 2545 2548 4 Decimal
## 483 2549 2552 4 Decimal
## 484 2553 2556 4 Decimal
## 485 2557 2558 2 Integer
## 486 2559 2562 4 Integer
## description comments
## 481 Partially Proficient Percentage One implied decimal
## 482 Proficient Percentage One implied decimal
## 483 Advanced Proficient Percentage One implied decimal
## 484 Scale Score Mean One implied decimal
## 485 Grade Level Located in text file only
## 486 Test Year
## valid_values
## 481 0.0 to 100.0 for spreadsheet and 0000 to 1000 for text file. Blank if Number Enrolled = 0 or if Number of Valid Scales Scores = 0 for both unsuppressed and suppressed files.
## 482 0.0 to 100.0 for spreadsheet and 0000 to 1000 for text file. Blank if Number Enrolled = 0 or if Number of Valid Scales Scores = 0 for both unsuppressed and suppressed files.
## 483 0.0 to 100.0 for spreadsheet and 0000 to 1000 for text file. Blank if Number Enrolled = 0 or if Number of Valid Scales Scores = 0 for both unsuppressed and suppressed files.
## 484 100.0 to 300.0 for spreadsheet and 1000 to 3000 for text file. Blank if Number Enrolled = 0 or if Number of Valid Scales Scores = 0 for both unsuppressed and suppressed files.
## 485 03, 04
## 486 2007
## spanner1 spanner2
## 481 NON-ECONOMICALLY DISADVANTAGED SCIENCE
## 482 NON-ECONOMICALLY DISADVANTAGED SCIENCE
## 483 NON-ECONOMICALLY DISADVANTAGED SCIENCE
## 484 NON-ECONOMICALLY DISADVANTAGED SCIENCE
## 485
## 486
## final_name
## 481 NON-ECONOMICALLY_DISADVANTAGED_SCIENCE_Partially_Proficient_Percentage
## 482 NON-ECONOMICALLY_DISADVANTAGED_SCIENCE_Proficient_Percentage
## 483 NON-ECONOMICALLY_DISADVANTAGED_SCIENCE_Advanced_Proficient_Percentage
## 484 NON-ECONOMICALLY_DISADVANTAGED_SCIENCE_Scale_Score_Mean
## 485 Grade_Level
## 486 Test_Year
Save:
save(layout_njask07gr3, file = paste0(final_path, 'datasets/njask07gr3_layout.rda'))
## Warning in gzfile(file, "wb"): cannot open compressed file 'datasets/
## njask07gr3_layout.rda', probable reason 'No such file or directory'
## Error in gzfile(file, "wb"): cannot open the connection
2006 gr 3 NJASK
sooooo many little changes to these layouts.
Read:
njask06gr3 <- readr::read_csv(paste0(final_path, 'datasets/njask2006gr3_layout.csv'))
## Error: 'datasets/njask2006gr3_layout.csv' does not exist in current working directory ('/Users/almartin/Google Drive/repositories/almart.in-source/content/pages').
names(njask06gr3) <- tolower(gsub(' ', '_', names(njask06gr3)))
## Error in gsub(" ", "_", names(njask06gr3)): object 'njask06gr3' not found
head(njask06gr3)
## Error in head(njask06gr3): object 'njask06gr3' not found
Process:
layout_njask06gr3 <- process_layout(njask06gr3)
## Error in filter_(.data, .dots = lazyeval::lazy_dots(...)): object 'njask06gr3' not found
layout_njask06gr3 %>% head()
## field_start_position field_end_position field_length data_type
## 1 1 9 9 Text
## 2 1 2 2 Text
## 3 3 6 4 Text
## 4 7 9 3 Text
## 5 10 59 50 Text
## 6 60 109 50 Text
## description comments
## 1 CDS Code
## 2 County Code
## 3 District Code
## 4 School Code
## 5 County Name
## 6 District Name
## valid_values
## 1 CDS codes for schools and districts\nTHE FIRST TWO POSITIONS WILL INCLUDE THE FOLLOWING AGGREGATION CODES: NS = Non-Special Needs; SN = Special Needs; ST = State; A = DFG A; B = DFG B; CD= DFG CD\x85.
## 2 01, 03, 05, 07, 09, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 80, 90
## 3 0100 to 9999
## 4 001 to 999
## 5 A to Z, blank; Applicable only for district and school aggregations
## 6 A to Z, blank; Applicable only for district and school aggregations
## spanner1 spanner2 final_name
## 1 CDS_Code
## 2 County_Code
## 3 District_Code
## 4 School_Code
## 5 County_Name
## 6 District_Name
layout_njask06gr3 %>% tail()
## field_start_position field_end_position field_length data_type
## 455 2409 2414 6 Integer
## 456 2415 2418 4 Decimal
## 457 2419 2422 4 Decimal
## 458 2423 2426 4 Decimal
## 459 2427 2430 4 Decimal
## 460 2431 2432 2 Integer
## description comments
## 455 Number of Valid Scale Scores
## 456 Partially Proficient Percentage One implied decimal
## 457 Proficient Percentage One implied decimal
## 458 Advanced Proficient Percentage One implied decimal
## 459 Scale Score Mean One implied decimal
## 460 Grade Located in text file only
## valid_values spanner1 spanner2
## 455 0 or greater SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 456 0.0 to 100.0 SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 457 0.0 to 100.0 SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 458 0.0 to 100.0 SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 459 100.0 to 300.0 SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 460 03, 04
## final_name
## 455 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Number_of_Valid_Scale_Scores
## 456 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Partially_Proficient_Percentage
## 457 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Proficient_Percentage
## 458 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Advanced_Proficient_Percentage
## 459 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Scale_Score_Mean
## 460 Grade
Save:
save(layout_njask06gr3, file = paste0(final_path, 'datasets/njask06gr3_layout.rda'))
## Warning in gzfile(file, "wb"): cannot open compressed file 'datasets/
## njask06gr3_layout.rda', probable reason 'No such file or directory'
## Error in gzfile(file, "wb"): cannot open the connection
2006 gr 5 NJASK
sigh.
Read:
njask06gr5 <- readr::read_csv(paste0(final_path, 'datasets/njask2006gr5_layout.csv'))
## Error: 'datasets/njask2006gr5_layout.csv' does not exist in current working directory ('/Users/almartin/Google Drive/repositories/almart.in-source/content/pages').
names(njask06gr5) <- tolower(gsub(' ', '_', names(njask06gr5)))
## Error in gsub(" ", "_", names(njask06gr5)): object 'njask06gr5' not found
head(njask06gr5)
## Error in head(njask06gr5): object 'njask06gr5' not found
Process:
layout_njask06gr5 <- process_layout(njask06gr5)
## Error in filter_(.data, .dots = lazyeval::lazy_dots(...)): object 'njask06gr5' not found
layout_njask06gr5 %>% head()
## field_start_position field_end_position field_length data_type
## 1 1 9 9 Text
## 2 1 9 9 Text
## 3 1 2 2 Text
## 4 3 6 4 Text
## 5 7 9 3 Text
## 6 10 59 50 Text
## description comments
## 1 RECORD KEY
## 2 CDS Code
## 3 County Code
## 4 District Code Applicable only for district and school aggregations.
## 5 School Code Applicable only for school aggregations.
## 6 County Name
## valid_values
## 1
## 2 CDS codes for schools and districts\nTHE FIRST TWO POSITIONS WILL INCLUDE THE FOLLOWING AGGREGATION CODES IN LIEU OF THE COUNTY CODE: ST = State; A = DFG A; B = DFG B; CD= DFG CD\x85.
## 3 01, 03, 05, 07, 09, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 80, 90
## 4 0100 to 9999, blank
## 5 001 to 999, blank
## 6 A to Z, blank; Applicable only for district and school aggregations
## spanner1 spanner2 final_name
## 1 RECORD_KEY
## 2 CDS_Code
## 3 County_Code
## 4 District_Code
## 5 School_Code
## 6 County_Name
layout_njask06gr5 %>% tail()
## field_start_position field_end_position field_length data_type
## 458 2403 2408 6 Integer
## 459 2409 2414 6 Integer
## 460 2415 2418 4 Decimal
## 461 2419 2422 4 Decimal
## 462 2423 2426 4 Decimal
## 463 2427 2430 4 Decimal
## description comments valid_values
## 458 Number of Voids Blank
## 459 Number of Valid Scale Scores Blank
## 460 Partially Proficient Percentage One implied decimal Blank
## 461 Proficient Percentage One implied decimal Blank
## 462 Advanced Proficient Percentage One implied decimal Blank
## 463 Scale Score Mean One implied decimal Blank
## spanner1 spanner2
## 458 SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 459 SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 460 SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 461 SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 462 SCIENCE NON-ECONOMICALLY DISADVANTAGED
## 463 SCIENCE NON-ECONOMICALLY DISADVANTAGED
## final_name
## 458 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Number_of_Voids
## 459 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Number_of_Valid_Scale_Scores
## 460 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Partially_Proficient_Percentage
## 461 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Proficient_Percentage
## 462 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Advanced_Proficient_Percentage
## 463 SCIENCE_NON-ECONOMICALLY_DISADVANTAGED_Scale_Score_Mean
Save:
save(layout_njask06gr5, file = paste0(final_path, 'datasets/njask06gr5_layout.rda'))
## Warning in gzfile(file, "wb"): cannot open compressed file 'datasets/
## njask06gr5_layout.rda', probable reason 'No such file or directory'
## Error in gzfile(file, "wb"): cannot open the connection
2009 NJASK
Read:
njask09 <- readr::read_csv(paste0(final_path, 'datasets/njask2009_layout.csv'))
## Error: 'datasets/njask2009_layout.csv' does not exist in current working directory ('/Users/almartin/Google Drive/repositories/almart.in-source/content/pages').
names(njask09) <- tolower(gsub(' ', '_', names(njask09)))
## Error in gsub(" ", "_", names(njask09)): object 'njask09' not found
head(njask09)
## Error in head(njask09): object 'njask09' not found
Process:
layout_njask09 <- process_layout(njask09)
## Error in filter_(.data, .dots = lazyeval::lazy_dots(...)): object 'njask09' not found
layout_njask09 %>% head()
## Error in eval(expr, envir, enclos): object 'layout_njask09' not found
layout_njask09 %>% tail()
## Error in eval(expr, envir, enclos): object 'layout_njask09' not found
Save:
save(layout_njask09, file = paste0(final_path, 'datasets/njask09_layout.rda'))
## Error in save(layout_njask09, file = paste0(final_path, "datasets/njask09_layout.rda")): object 'layout_njask09' not found